跟着动画学最小二乘法:从直觉到矩阵推导
发展历程¶
最小二乘法(Least Squares Method)是一种数学优化技术,广泛用于数据拟合、回归分析等领域。最小二乘法起源于18世纪,最早由 卡尔·弗里德里希·高斯(Carl Friedrich Gauss) 和 阿德里安-马里·勒让德(Adrien-Marie Legendre) 提出。1801年,高斯在预测小行星谷神星的轨道时使用了最小二乘法,并于1809年在《天体运动论》中正式发表相关理论。 1805年,勒让德在《新方法》中首次公开描述了最小二乘法,称其为“méthode des moindres carrés”(最小平方方法)。
两人关于谁是首创者存在争议,但高斯声称他在1795年就已使用该方法。到19世纪,高斯进一步发展了最小二乘法的理论基础,结合概率论和正态分布,建立了误差分析的统计框架。
动画演示¶
最小二乘法是一种通用的数学优化技术,是一个广义的、总称性的概念。最小二乘法的核心目标是通过最小化观测值与模型预测值之间的误差平方和,找到最佳的模型参数。
这个“最小化误差平方和”的核心思想,可以被应用到各种不同的模型和场景中,从而衍生出许多变体。本篇文章研究的是最小二乘法在标准线性回归问题上的经典应用,即普遍最小二乘法(Ordinary Least Squares,简称OLS)。当人们提到“用最小二乘法做线性回归”时,绝大多数情况下指的就是OLS。
除了OLS,最小二乘法家族还包括加权最小二乘法(WLS)、交替最小二乘法(ALS)和偏最小二乘法(PLS)等,它们都是为了解决特定问题或放宽某些假设而发展出的更复杂的变体。
下面观察一个最简单的例子,用最小二乘法求解一个数据集的直线。

一句话直觉:给你一堆散点,OLS 帮你找一条直线,让所有点到这条线的"垂直距离的平方"加起来最小。
如果你只看动画就能感受到"直线在转、正方形在缩、最后停下来"这个过程,那你就已经抓住了 OLS 的全部直觉。本文把这件事的数学讲清楚——从"为什么要平方"的几何类比出发,一步步走到矩阵推导、正规方程、投影视角,再到 Gauss–Markov 统计性质。每节先给直觉、再给推导,初学者能跟上,有基础的读者能读到底。
问题设定¶
直觉:想象你是一个调音师,面前有 \(n\) 个旋钮(数据点),每个都偏离了"理想位置"一段距离。你想转一个总旋钮(直线的斜率和截距),让所有偏差整体最小。
给定 \(n\) 个观测点 \(\{(x_i, y_i)\}_{i=1}^{n}\),我们想用一条直线
去拟合这组数据。问题是:什么样的 \((\beta_0, \beta_1)\) 是"最好"的?
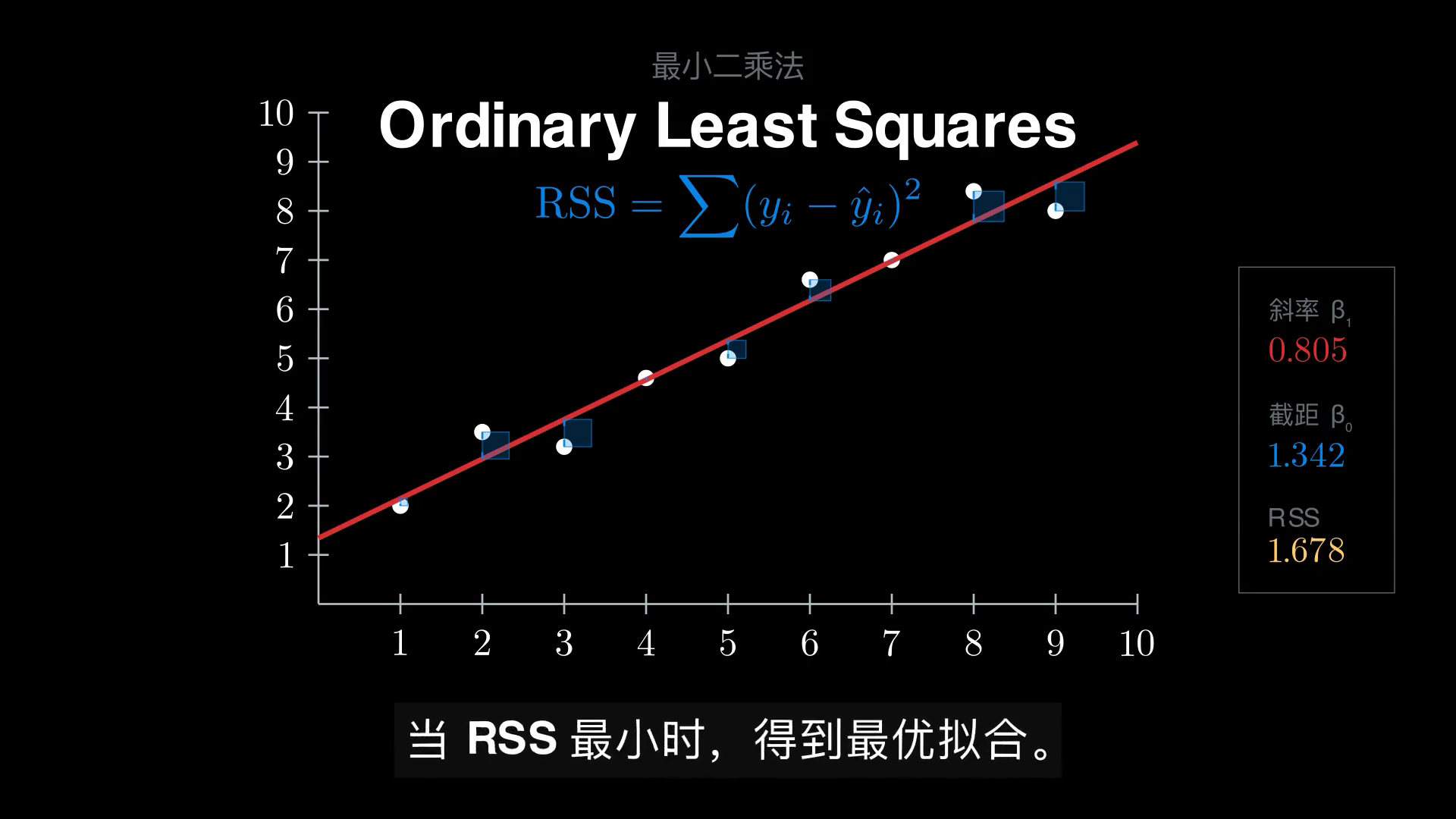
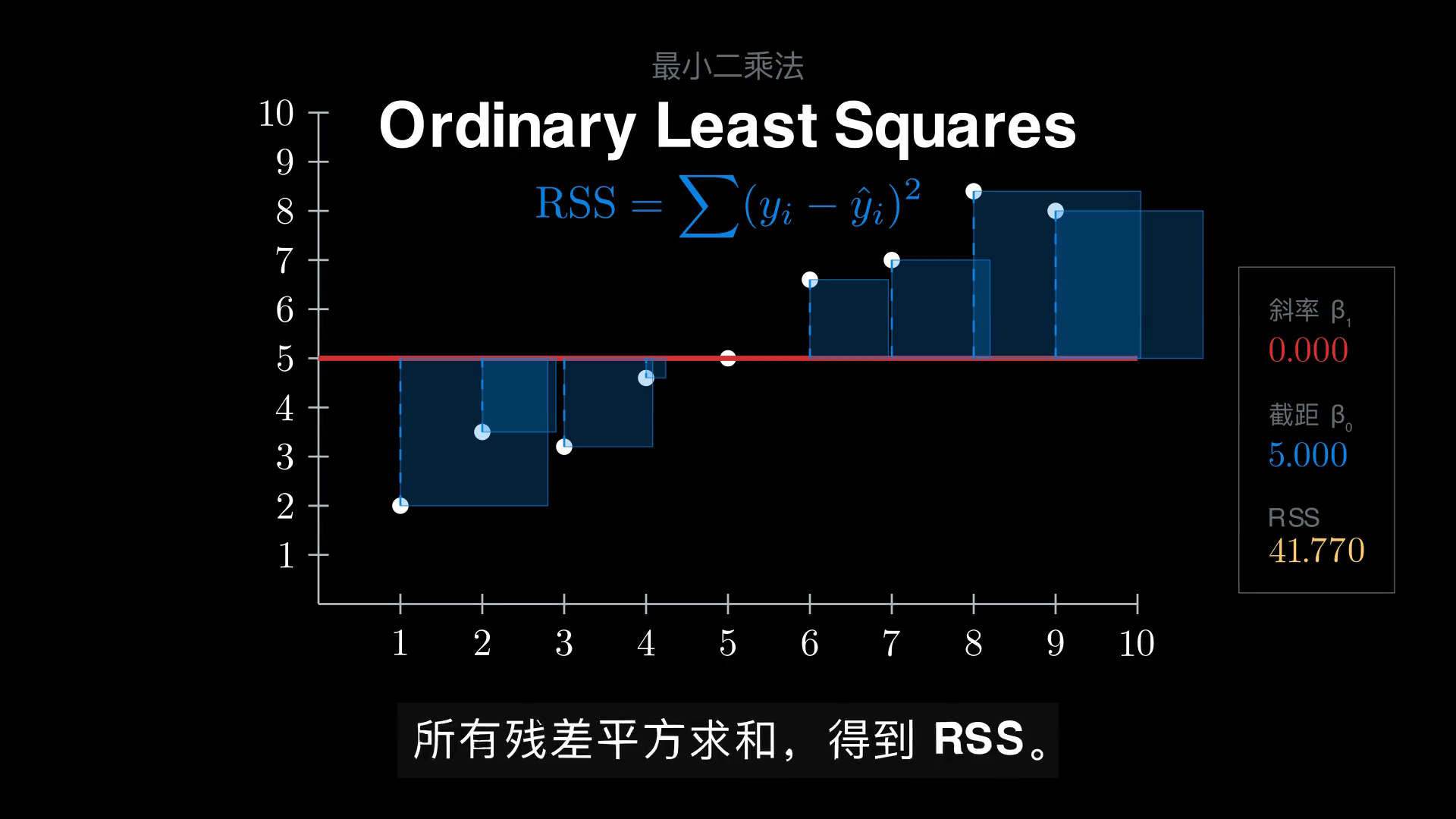
OLS 给出的回答是:让所有观测点到直线的垂直距离的平方和最小。
定义残差
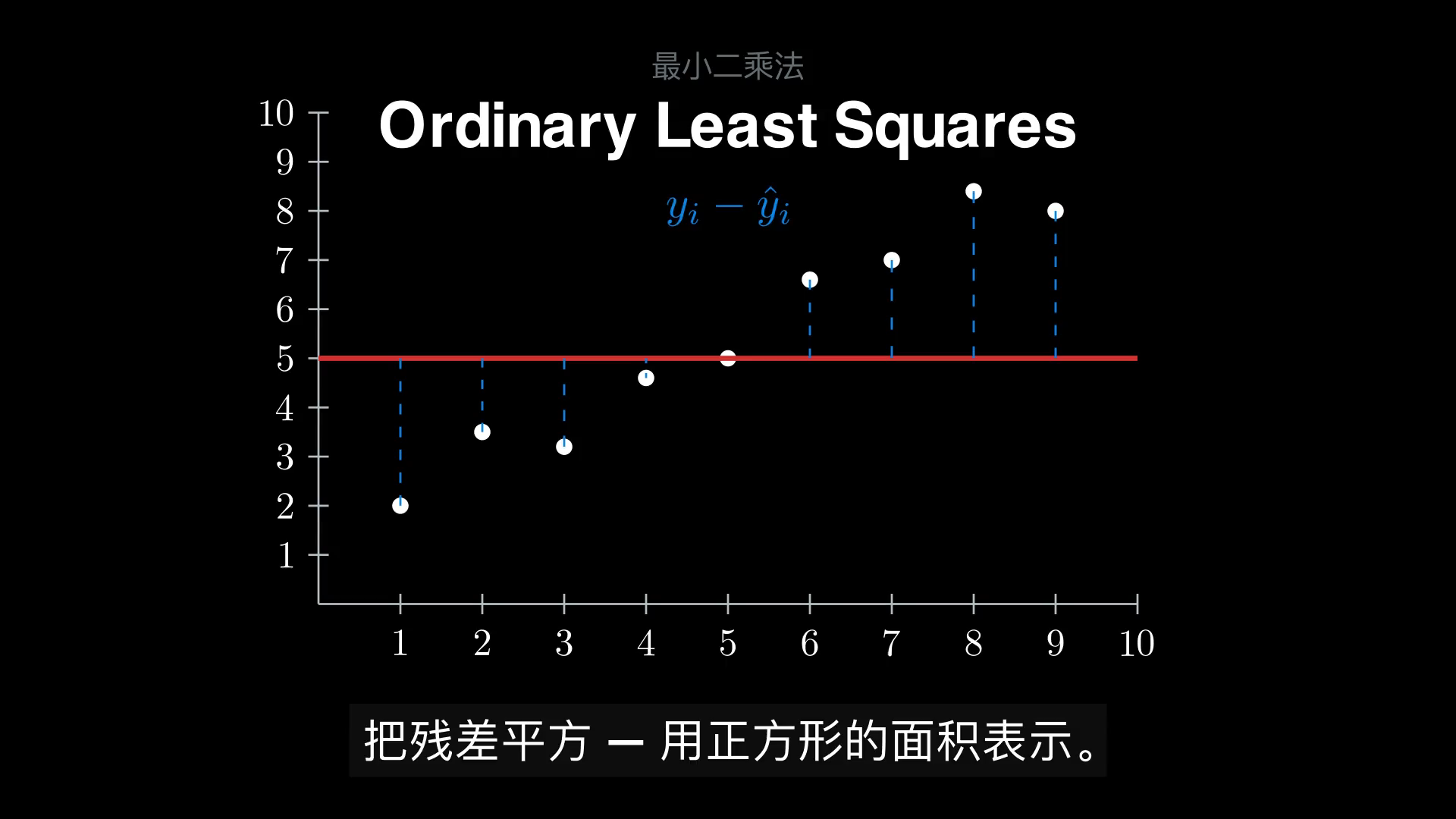
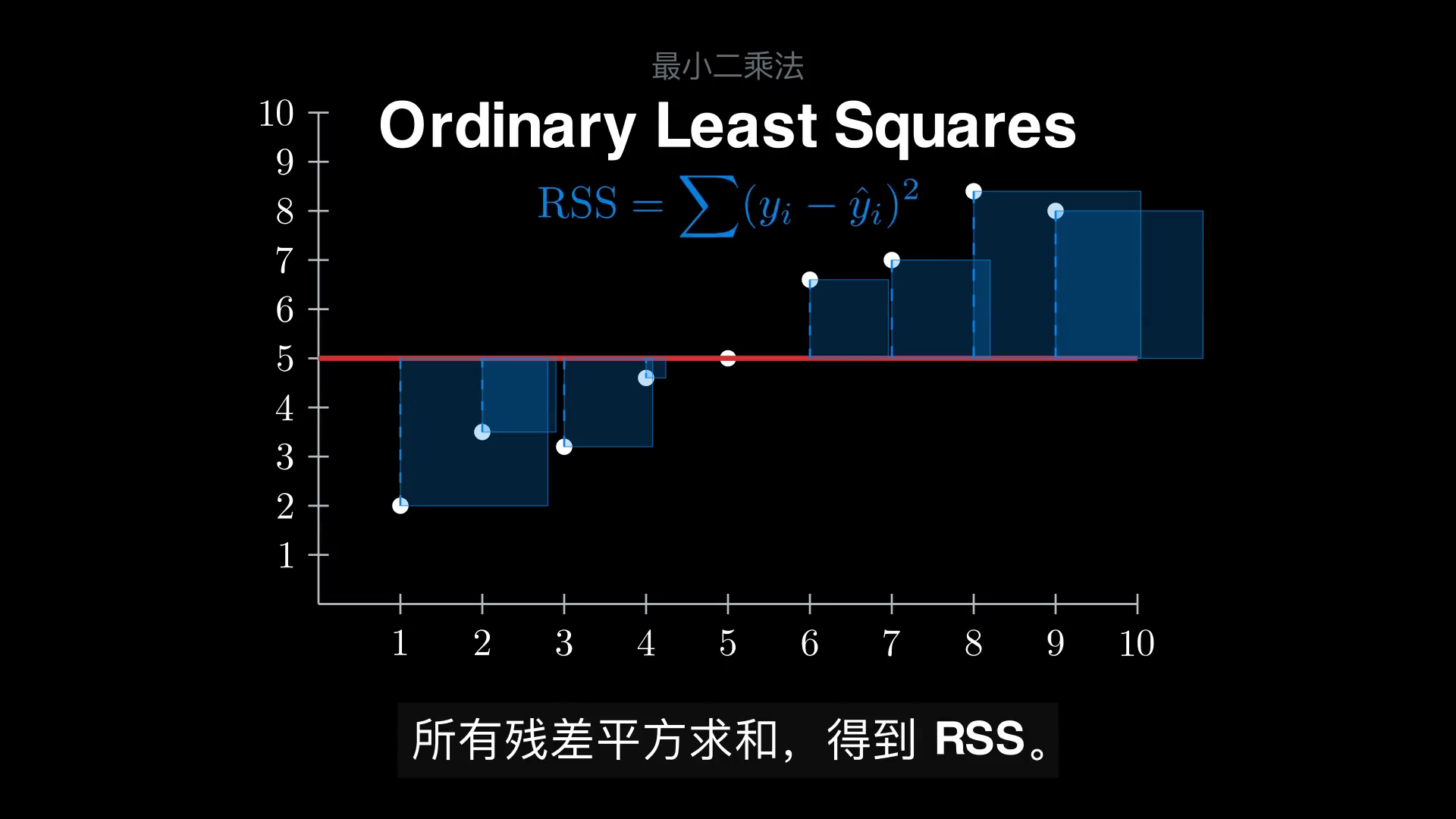
目标函数(残差平方和,Residual Sum of Squares)为
矩阵形式¶
直觉:把 \(n\) 个方程叠起来写成矩阵,等价于把"一堆零散的等式"换成"一个紧凑的向量方程"。这么做不是为了装高级,而是为了能用线性代数的工具(投影、求逆)直接解出来。
把 \(n\) 个方程叠起来。设
则 \(\hat{\boldsymbol{y}} = X\boldsymbol{\beta}\),残差向量 \(\boldsymbol{\varepsilon} = \boldsymbol{y} - X\boldsymbol{\beta}\),目标函数变成二次型
展开:
这一步在干嘛?
把平方和展开后,得到三项——数据的总能量 \(\boldsymbol{y}^\top\boldsymbol{y}\)(与 \(\boldsymbol{\beta}\) 无关,可忽略)、一次项 \(-2\boldsymbol{\beta}^\top X^\top\boldsymbol{y}\)、二次项 \(\boldsymbol{\beta}^\top X^\top X\boldsymbol{\beta}\)。RSS 现在是 \(\boldsymbol{\beta}\) 的二次函数,意味着它有一个唯一的极小点(只要 \(X^\top X\) 正定)——这正是闭式解存在的前提。
求解:正规方程¶
直觉:二次函数的极小点在哪?在导数为零的地方。对向量 \(\boldsymbol{\beta}\) 求"导"就是求梯度,令梯度为零得到线性方程组,解出来就是答案。
对 \(\boldsymbol{\beta}\) 求梯度并令其为零:
得到正规方程(Normal Equations):
当 \(X^\top X\) 可逆(即 \(X\) 列满秩,等价于 \(x_i\) 不全相等)时,唯一解为
这行公式在告诉我们什么?
最优参数 \(\hat{\boldsymbol{\beta}}\) 是数据通过 \((X^\top X)^{-1} X^\top\) 这个矩阵的线性变换。换句话说,回归系数是观测值 \(\boldsymbol{y}\) 的某种"加权平均"——每个 \(y_i\) 对 \(\hat{\boldsymbol{\beta}}\) 的贡献由 \(X\) 的结构决定。
标量形式¶
把 \(X^\top X\) 和 \(X^\top \boldsymbol{y}\) 显式写出:
解这个 2×2 线性方程组,得到教科书最常见的两个公式:
第二个等号用了中心化形式——分子是 \(x\) 与 \(y\) 的协方差(乘 \(n\)),分母是 \(x\) 的方差(乘 \(n\)),所以
直觉读法
斜率 = 协方差 / 方差。如果 \(x\) 和 \(y\) 同步涨跌(协方差正),斜率为正;如果 \(x\) 自己都不怎么变(方差小),稍微一点同步就会让斜率变大——这其实是"分母小导致估计不稳定"的根源,统计学里叫"弱工具变量"问题。
下面代码演示用的就是这个标量形式:
slope = (n * sum_xy - sum_x * sum_y) / (n * sum_xx - sum_x * sum_x)
intercept = (sum_y - slope * sum_x) / n
矩阵解与标量公式的关系
第 3 节的 \(\hat{\boldsymbol{\beta}} = (X^\top X)^{-1} X^\top \boldsymbol{y}\) 是通用形式,对任意列数的 \(X\) 都成立;标量公式只是 \(X \in \mathbb{R}^{n\times 2}\) 时的特例。多元回归时直接用矩阵形式,不必再展开成标量求和——这就是矩阵记法的威力。
几何解释:投影¶
直觉:把数据看成高维空间里的一个向量,回归直线所在的方向是另一个低维子空间。OLS 干的事,就是把这个数据向量"垂直地"投影到那个子空间上——影子就是预测值,与真值的差就是残差,且残差必然垂直于子空间。
\(\hat{\boldsymbol{y}} = X\hat{\boldsymbol{\beta}}\) 是 \(X\) 的列空间 \(\mathrm{col}(X)\) 中的一个向量。正规方程等价于
也就是 残差向量 \(\boldsymbol{y} - \hat{\boldsymbol{y}}\) 与 \(X\) 的每一列正交。这说明 \(\hat{\boldsymbol{y}}\) 是 \(\boldsymbol{y}\) 在 \(\mathrm{col}(X)\) 上的正交投影。
投影矩阵为
为什么这条视角重要?
投影视角把 OLS 从"算方程"提升到"看几何"。多元回归、岭回归、加权回归,本质上都是改这个投影矩阵 \(P\) 的形式。理解了投影,就理解了一整族方法的母题。
为什么用"平方"而不只是"绝对值"?¶
现实类比:调音师为什么用"误差平方"而不是"误差绝对值"作为总指标?因为平方对大误差更敏感——一个偏差 10 的旋钮贡献 100 分,十个偏差 1 的旋钮才贡献 10 分。这迫使你优先修最离谱的那个,而不是装作没看见。
把每个残差 \(\varepsilon_i\) 想象成一个正方形的边长,那么 \(\varepsilon_i^2\) 就是这个正方形的面积。OLS 等价于最小化所有正方形面积之和——这正是动画里把残差画成正方形的几何直喻。
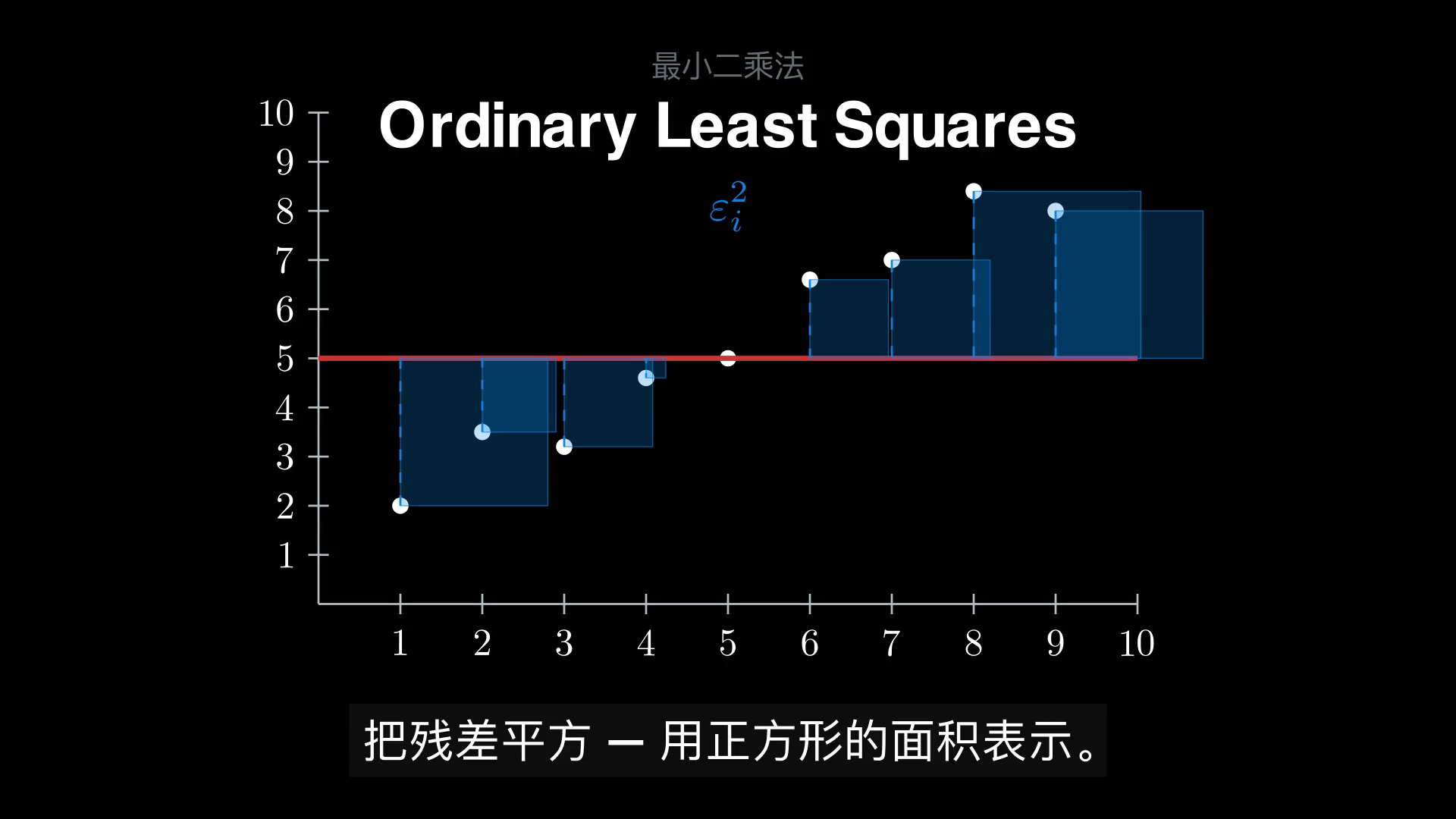
平方损失相比绝对值损失有几个关键优势:
- 处处可导。\(|x|\) 在 \(x=0\) 不可导,平方 \(x^2\) 处处光滑,所以能闭式求导得正规方程。绝对值损失(LAD)要靠线性规划或迭代算法求解。
- 正负残差对称抵消被消除。\(\sum \varepsilon_i = 0\) 不能保证拟合好(一个 +100 和一个 -100 抵消为 0 但很糟),平方后无法抵消。
- 对离群点更敏感。残差 10 比残差 1 贡献大 100 倍,相当于自动给大误差更高权重。
- 统计意义:在 Gauss–Markov 假设下(\(\varepsilon_i\) 独立、零均值、同方差、不要求正态),OLS 是最优线性无偏估计(BLUE)——这条定理叫 Gauss–Markov 定理。如果再加正态性假设,OLS 还等于极大似然估计。
代价是平方损失对离群点过于敏感——这正是后续 robust regression、Huber loss 要解决的问题。
进阶:统计性质¶
在标准假设 \(\boldsymbol{y} = X\boldsymbol{\beta}^* + \boldsymbol{\varepsilon}\),\(\mathbb{E}[\boldsymbol{\varepsilon}]=\boldsymbol{0}\),\(\mathrm{Cov}(\boldsymbol{\varepsilon})=\sigma^2 I\) 下:
- 无偏性:\(\mathbb{E}[\hat{\boldsymbol{\beta}}] = \boldsymbol{\beta}^*\)。
- 协方差:\(\mathrm{Cov}(\hat{\boldsymbol{\beta}}) = \sigma^2 (X^\top X)^{-1}\)。这条公式给出 \(\hat{\beta}_0, \hat{\beta}_1\) 的标准误,是 t 检验、置信区间的基础。
- Gauss–Markov:在所有线性无偏估计中,OLS 方差最小(BLUE)。
- \(\sigma^2\) 估计:\(\hat{\sigma}^2 = \mathrm{RSS}/(n-2)\),分母减 2 是因为估计了 2 个参数(自由度修正)。
- \(R^2\):\(R^2 = 1 - \mathrm{RSS}/\mathrm{TSS}\),其中 \(\mathrm{TSS} = \sum (y_i - \bar{y})^2\)。\(R^2 \in [0,1]\) 衡量模型解释了多少方差。
推广¶
OLS 是一大类方法的母题:
- 多元线性回归:\(X\) 列数变多,公式 \(\hat{\boldsymbol{\beta}} = (X^\top X)^{-1} X^\top \boldsymbol{y}\) 一字不改。
- 加权最小二乘(WLS):\(\min \sum w_i \varepsilon_i^2\),对应 \(\hat{\boldsymbol{\beta}} = (X^\top W X)^{-1} X^\top W \boldsymbol{y}\)。
- 岭回归:\(\min \|\boldsymbol{y} - X\boldsymbol{\beta}\|^2 + \lambda \|\boldsymbol{\beta}\|^2\),闭式解 \(\hat{\boldsymbol{\beta}} = (X^\top X + \lambda I)^{-1} X^\top \boldsymbol{y}\),解决 \(X^\top X\) 病态或不可逆问题。
- 广义线性模型:把平方损失换成指数族分布的负对数似然,得到 logistic、Poisson 等回归。
掌握 OLS 的矩阵推导和投影视角,相当于拿到了进入这一整族方法的钥匙。